Datarepository Unive SBA research support
- Research data management support: openscience@unive.it
What is Datarepository Unive
Datarepository Unive is the institutional, free, and open repository that collects, stores, and preserves research data produced by Ca' Foscari researchers according to the highest international standards and best practices.
Preserving data does not necessarily mean making it open. Even when data cannot be shared, depositing it in Datarepository Unive is recommended to ensure safe storage.
Datarepository Unive is a platform that helps researchers to manage their research data. It does not allow depositing publications, which must be archived in ARCA.
Among the main benefits, with the Datarepository Unive you can:
- securely deposit data during or at the end of a research project
- share data related to publications according to FAIR principles
- assign DOIs to uploaded data for easy citation
- open up research data to other researchers, with the correct licences and in a controlled manner
- comply with funders' requirements for research data (Datarepository Unive meets the European Commission’s criteria for a 'trusted repository').
Depositing in Datarepository Unive
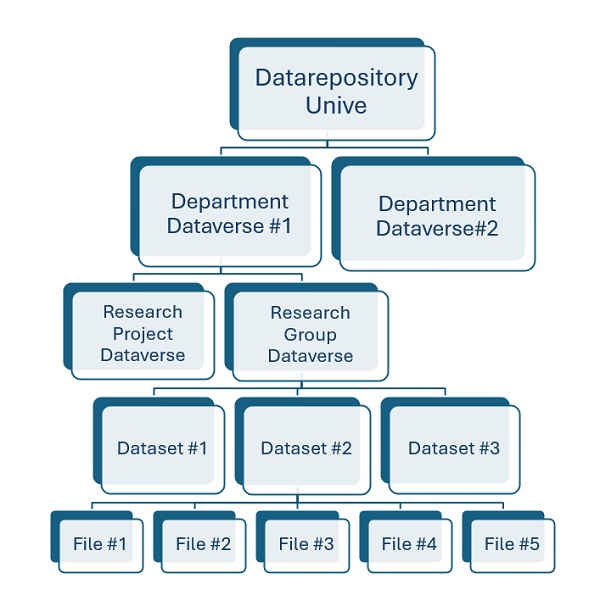
Structure of Datarepository Unive
Dataverse platform of Datarepository Unive has a hierarchical structure and can be defined as a large box containing 8 departmental dataverses (one for each Ca' Foscari department):
- each departmental dataverse can contain many dataverses, ideally one for each research project or research group
- every single dataverse is, in turn, a container for one or more datasets
- each dataset – endowed with a unique DOI – contains research data files
Who can deposit
According to the Research Data Management Policy, all members of the scientific community of Ca' Foscari University of Venice (researchers and staff) who create, collect and/or manage research data can deposit their datasets in the Datarepository Unive.
Check-list before you start
Before creating an account in Datarepository Unive and uploading your research data, please consider the following points carefully:
- ensure that you own the data or have obtained permission from relevant third parties
- verify data integrity and accessibility (uncorrupted data, non-proprietary formats, etc.)
- associate the dataset with accurate descriptions and metadata to facilitate reuse and understanding and document how the data was acquired
- specify the conditions for re-use under the appropriate licence (CC or other)
- assess the benefits of depositing the dataset, including its significance, uniqueness, acquisition costs, links to other datasets, and potential for re-use
- verify compliance with data protection laws, including anonymisation and restricted access measures
- consider all ethical aspects. Scientific ethics encourages transparency, sharing, and data publication, but it is essential to consider potential misuse of the data. Please visit the Ethics Commission page if you need help or more information.
What to deposit
After considering all the items in the above-mentioned check-list, please evaluate the types of data you want to store and publish:
- raw data: original data collected during research but not yet processed
- processed data: data derived from the cleaning, anonymising and checking the original data. They comply with FAIR principles
- analysed data: data resulting from the analysis and/or integration of processed data. It can take the form of tables, texts or graphs to facilitate understanding and communication
File format: please see the recommended data formats for depositing on a dataverse according to FAIR principles.
Use licence: according to the principles of Open Science (see Research Data Management Policy), research results should be made accessible under a free-use licence that guarantees the transparency of uses and verifiability of sources. Where applicable, it is recommended to use Creative Commons licenses, specifically the CC-BY license for data and the CC0 (public domain) license for metadata. As an administrator, you can establish terms of use for each dataset and customise the terms of use, for example, to protect data granted by third parties.
How to deposit
To access, you must log in with your University credentials at https://datarepository.unive.it.
To deposit data in a new dataverse, the researcher or PI must submit a 'New dataverse request', unless the Department has established a different procedure.
The dataverse administrator can manage the roles of other contributors – if any – and manage the upload of one or more datasets with metadata and licences.
The Open Science Working Group (GLOS) verifies the compliance of metadata and licences before releasing publication.
The dataverse/dataset remains 'unpublished' until the Open Science Working Group (GLOS) verifies the metadata and releases the publication.
Guide
| Terms of use | 93 K |
Insights
Data Management Plan
Research projects funded by public and private organisations that generate open or closed data require a Data Management Plan (DMP). A DMP is a concise document describing how data will be managed, used, and archived throughout and after the research and how it will be disseminated and reused. A DMP also addresses any ethical considerations related to the project.
The DMP plans and communicates, from the beginning of the activity, how the data and associated metadata will be collected, preserved, reused and disseminated. The richer the metadata, the greater the data's discoverability.
The DMP is developed by the principal investigator using templates (such as those provided by DCC, Data Stewardship Wizard, easyDMP, and OpenAIRE's Argos) and encompasses the entire data lifecycle. It ensures traceability, availability, authenticity, citability, proper preservation, compliance with legal requirements, and adequate security measures to regulate its future use.
DMP and ethical implications
The ethics committee should be consulted when a research project involves activities that involve collecting personal data, in terms of both quantity (the number of personal information collected) and quality (personal data that may reveal an individual's racial or ethnic origin, sexual orientation, political opinions, religious or philosophical beliefs, or trade union membership, as well as genetic and biometric data or health-related data). The ethics committee's opinion safeguards both researchers and participants in research activities.
For more information please visit Ca' Foscari’s Ethics Committee page - Data Management Plan (DMP) section.
FAIR data
The application of the FAIR principles requires that the data be:
- Findable: traceable through unique persistent identifiers (DOIs) and metadata built according to international standards (Dublin Core, DCC guide for Metadata standards, etc.).
- Accessible: data and metadata must be accessible to humans and machines through storage in repositories and standard protocols. Metadata must be available even when the data is not open access. Accessibility does not mean 'open data' (authentication and authorisation systems may exist).
- Interoperable: data should be saved in non-proprietary, uncompressed, unencrypted formats, with documented standards that can be processed by operating systems using vocabularies that follow FAIR principles.
- Reusable: to be reusable, data must be accompanied by a clear and accessible data usage license (CC-BY or CC0) and detailed provenance.
For more information on the FAIR principles, with examples and insights, and to check whether your data is FAIR, see GO-FAIR, FAIR assessment tool and FAIR Aware.
The correct implementation of the data management plan (DMP) ensures that the research data is compatible with the FAIR principles.
Metadata
Metadata, by definition, provides information about other data. It is structured information associated with an object for discovery, description, use, management and preservation.
To be 'machine-readable', metadata must follow predefined standard schemas and syntaxes (e.g. Dublin Core).
- Descriptive metadata
used to find or understand a resource
examples: title, author, subject, keywords, date - Technical metadata
used to decode files
examples: file format and size, device, version, date/time of creation - Legal metadata
used to ascertain intellectual property
examples: CC licences
Last update: 09/04/2025