Datarepository Unive Supporto ricerca SBA
- Supporto alla gestione dei dati della ricerca: openscience@unive.it
Il Datarepository Unive
Datarepository Unive è il repository istituzionale, gratuito e aperto che raccoglie, archivia e conserva i dati delle ricerche prodotte da ricercatrici e ricercatori di Ca' Foscari secondo i più elevati standard e le buone pratiche internazionali.
Preservare i dati non significa necessariamente renderli aperti: anche quando non è possibile condividere i dati, è opportuno depositarli in Datarepository Unive, per garantire loro un'archiviazione sicura.
Datarepository Unive è la piattaforma che aiuta i ricercatori a gestire i dati della ricerca; non prevede invece il deposito delle pubblicazioni, che vanno archiviate in ARCA.
I principali vantaggi di Datarepository Unive sono:
- archiviare i dati in modo sicuro durante o al termine di un progetto di ricerca
- condividere i dati associati alle pubblicazioni secondo i principi FAIR
- assegnare DOI ai dati caricati per poterli facilmente citare
- aprire i dati della ricerca ad altri ricercatori, con le corrette licenze e in modo controllato
- rispettare i requisiti dei finanziatori in merito ai dati di ricerca (Datarepository Unive risponde ai criteri individuati dalla Commissione Europea per la definizione di “trusted repository”)
Depositare nel Datarepository Unive
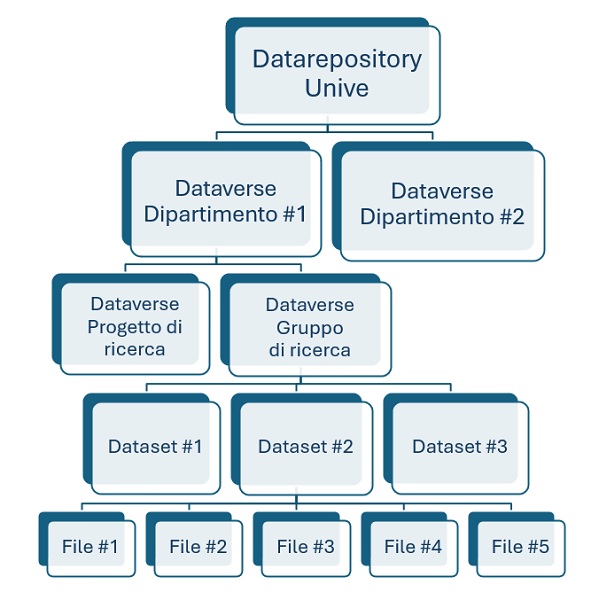
La struttura di Datarepository Unive
La piattaforma Dataverse su cui si basa il repository ha una struttura gerarchica.
Datarepository Unive può essere definito come un grande contenitore che ha al suo interno 8 dataverse dipartimentali (uno per ognuno degli 8 dipartimenti di Ca' Foscari):
- ogni dataverse dipartimentale può contenere molti dataverse, idealmente uno per ogni ricercatore o progetto collaborativo di ricerca
- ogni singolo dataverse è a sua volta un contenitore di uno o più dataset
- ogni dataset – dotato di un DOI univoco – contiene infine i file con i dati della ricerca
Chi può depositare
In base alla Policy per la gestione dei dati della ricerca possono depositare i propri dataset in Datarepository Unive i membri della comunità scientifica dell’Università Ca’ Foscari Venezia (ricercatori, ricercatrici e staff) che creano, raccolgono e/o gestiscono i dati della ricerca.
Check list prima di iniziare
Prima di creare un account in Datarepository Unive e caricare i dati della ricerca, considera attentamente questi punti:
- sei il proprietario/la proprietaria dei dati (o hai il permesso delle terze parti coinvolte)
- hai assicurato l’integrità e accessibilità ai dati (dati non corrotti, formati non proprietari ecc.)
- hai associato al tuo dataset le corrette descrizioni per garantire il riuso e comprensione (metadati) nonché le modalità di acquisizione dei dati
- hai specificato le condizioni di riuso con una licenza adeguata (CC o altre)
- hai valutato i vantaggi del deposito di quello specifico dataset (significatività, unicità/singolarità, costi di acquisizione dei dati, collegamenti con altri dataset, potenziale riuso, ecc.)
- hai adottato le corrette misure previste dalla normativa sulla protezione dei dati (anonimizzazione, accesso ristretto, ecc.)
- hai considerato gli aspetti etici. Se da un lato l’etica scientifica incoraggia la trasparenza dei dati, la condivisione e la pubblicazione, è necessario interrogarsi se esista la possibilità di un uso distorto o improprio dei dati. Se hai bisogno di aiuto o di maggiori informazioni, consulta la pagina della Commissione etica.
Cosa depositare
Dopo aver considerato tutti gli aspetti elencati nella check list precedente, è opportuno valutare i tipi di dati che si intendono conservare e pubblicare:
- dati grezzi (raw data), dati originali raccolti durante il processo di ricerca, ma non ancora elaborati
- dati elaborati, derivati dalla pulizia, eventuale anonimizzazione e controllo dei dati originali; sono dati che rispondono ai principi FAIR
- dati analizzati, che derivano dall’analisi e/o dall’integrazione dei dati elaborati, e assumono la forma di rappresentazione tabellari, testuali, grafiche per facilitare la comprensione e comunicazione
Formati file: consulta i formati di dato raccomandati per il deposito [ENG], in linea coi principi FAIR.
Licenze di utilizzo: secondo i principi dell’Open Science e della Policy per la gestione dei dati della ricerca è raccomandabile rendere accessibile i risultati della ricerca tramite una licenza di libero utilizzo che garantisca la tracciabilità degli usi e il riconoscimento della fonte originaria. Comunemente adottate sono le licenze Creative Commons e in particolare la licenza CC-BY per i dati e della licenza CC0 (pubblico dominio) per i metadati. Come amministratrice/amministratore è possibile stabilire i termini di utilizzo di ciascun dataset e personalizzare i termini d’uso, per esempio per proteggere dati concessi da terze parti.
Come depositare
Per accedere è necessario fare il login su https://datarepository.unive.it con le credenziali d’Ateneo.
Per depositare i dati in un nuovo dataverse la ricercatrice/il ricercatore o referente di progetto (PI) invia una richiesta di ‘Nuovo dataverse’ salvo diversi accordi con il Dipartimento.
L’amministratrice/amministratore del dataverse potrà gestire – se previsti – i ruoli di altri collaboratori e gestire il caricamento di uno o più dataset corredandoli di metadati e licenze.
Il Gruppo di lavoro su Open Science (GLOS) verifica la conformità di metadati ai principi FAIR e licenze prima di rilasciare la pubblicazione.
Il dataverse/dataset resta 'unpublished' finché il Gruppo di lavoro su Open Science (GLOS) non verifica i metadati e valida la pubblicazione.
Approfondimenti
Data Management Plan
I progetti di ricerca finanziati da enti (pubblici e privati) che producono dati (aperti o chiusi) prevedono la redazione di un Data Management Plan (DMP), strumento operativo che descrive in modo sintetico e preciso le modalità di gestione, valorizzazione e preservazione nel tempo dei dati durante e dopo la ricerca, le modalità di riuso e diffusione, le eventuali implicazioni etiche del progetto.
Il DMP serve per programmare e comunicare, dall’inizio dell’attività, la raccolta, conservazione, riuso e divulgazione dei dati, unitamente ai metadati associati. Quanto più i metadati saranno ricchi, tanto maggiore sarà la discoverability del dato.
Il DMP è redatto dal principal investigator sotto forma di template (come quelli proposti da tool online DCC [ENG], Data Stewardship Wizard [ENG], easyDMP [ENG], Argos [ENG] di OpenAiRE) e rappresenta l’intero ciclo di vita del dato assicurandone tracciabilità, disponibilità, autenticità, citabilità, conservazione appropriata, adesione a parametri legali chiari e l’adozione di misure di sicurezza adeguate, che ne assicurano e disciplinano gli usi successivi.
DMP e implicazioni etiche
È opportuno consultare il comitato etico quando il progetto di ricerca prevede attività che prevedano la raccolta di dati personali, in termini di quantità (numero di informazioni personali raccolte) e qualità (dati personali che possono rivelare l’origine razziale ed etnica, l’orientamento sessuale, le opinioni politiche, le convinzioni religiose o filosofiche, o l’appartenenza sindacale di un individuo, o dati genetici e biometrici o relativi alla salute).
Il parere del comitato etico va a tutela dei ricercatori e dei partecipanti alle attività di ricerca.
Per maggiori informazioni consulta la pagina della Commissione etica di Ca’ Foscari - sezione Data Management Plan (DMP).
FAIR data
L’applicazione dei principi FAIR prevede che i dati siano:
- Findable: rintracciabili grazie a identificatori persistenti unici (DOI) e metadati costruiti secondo standard internazionali (Dublin Core [ENG], DCC guide for Metadata standards [ENG], ecc.).
- Accessible: dati e metadati devono poter essere accessibili dagli esseri umani e dalle macchine mediante il deposito in archivi o repository e l'uso di protocolli standard. Almeno i metadati devono essere disponibili anche quando i dati non sono open access. Accessibile non significa infatti “dato aperto” (possono essere previsti sistemi di autenticazione e autorizzazione).
- Interoperable: i dati dovrebbero essere salvati in formati non proprietari, non compressi, non criptati, con standard documentati, in grado di essere elaborati da sistemi operativi con linguaggi conformi ai principi FAIR.
- Reusable: per poter essere riusabili, i dati devono essere corredati da una licenza di utilizzo (CC-BY o CC0) e una documentazione con le informazioni relative alla loro formazione.
Per maggiori informazioni sui principi FAIR, con esempi e approfondimenti, e per autoverificare se i tuoi dati siano FAIR, consulta i siti GO-FAIR [ENG], FAIR assessment tool [ENG] e FAIR Aware [ENG].
La compatibilità dei dati prodotti dalla ricerca con i principi FAIR è garantita dalla corretta elaborazione del Data Management Plan (DMP).
Metadati
I metadati per definizione sono dati che forniscono informazioni su altri dati. Sono informazioni strutturate, associate a un oggetto per scopi di scoperta, descrizione, uso, gestione e conservazione.
I metadati, per essere “machine readable”, devono seguire schemi standard e sintassi predefiniti (per esempio Dublin Core [ENG]).
- Metadati descrittivi
servono a trovare o comprendere una risorsa
esempi: titolo, autore, soggetto, parole chiave, data - Metadati tecnici
servono a decodificare i file
esempi: formato e dimensione file, dispositivo, versione, data/ora di creazione - Metadati giuridici
servono a definire la proprietà intellettuale
esempi: licenze CC
Last update: 09/04/2025